之前写一个小项目需要用到过期缓存功能,因为想尽量轻量一些,只在内存中进行缓存,不打算走IO。虽说Python官方的lru_cache很好用,但是偏偏又不提供过期功能。简单搜了下,发现有人提供了一个附带过期功能的版本。代码如下所示:
1 | from datetime import datetime, timedelta |
看了下他的代码,实现方式很简单,就是在官方的lru_cache外面又包了一层,然后自己管理缓存的过期期限。但细看之后发现这个装饰器有个很大的问题,它会在过期的时候把所有缓存的函数返回结果清空掉,哪怕B比A要晚缓存了一个小时,只要A一过期,就会把其他的缓存一并清空掉。这显然不合理也不好用,理想情况应该是每个参数组合都有自己的过期期限,互相独立,互不干扰。
按理说这个逻辑并不复杂,只要在增加/获取缓存的同时,加上过期时间的存储和判断即可,原本我准备上面的样例那样给官方的装饰器再包装一层,但很快发现做不到这一点,因为官方的lru_cache只对外暴露了两个操作缓存的接口,分别是func.cache_info()和func.cache_clear(),查看缓存命中统计和清空缓存,没办法对cache字典的单个key进行操作(缓存其实就是存在了一个叫cache的字典里,后面看源码就知道了)。所以如果要对每个key做独立的过期,就必须改动内部逻辑了。其实到这里,从实用的角度出发,直接找第三方库是比较合理的。不过我出于兴趣,决定自己来实现一下。
要改,那么自然要先读。这里简单过一下Python3.6的lru_cache实现。
1 | def lru_cache(maxsize=128, typed=False): |
要读懂这段代码需要对Python的装饰器工作原理有一定了解,本文不做赘述。这段代码显然没涉及太多逻辑,开头校验下参数,把函数和装饰器参数传进了_lru_cache_wrapper函数,后面的update_wrapper只是做了些属性转移的工作,跟缓存功能没太大关系。我们再进到_lru_cache_wrapper函数看看,实际上主要的缓存逻辑实现都在这里头了。接下来分段来做解读。
1 | def _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo): |
这里基本都是些初始化,光看这部分可能会有点云里雾水的,主要还得看后面都对这些常量、变量做了些什么事情。先简单说下lru_cache的实现原理,它是借助Python字典和双向环形链表来实现的。
root就是这个链表的根节点,root是个数组,链表里的其他节点也是这个结构,分别包含四个部分:前节点(PREV),后节点(NEXT),字典键(KEY)和函数结果(RESULT)。在通常情况下,根节点的左侧(PREV)是最后被访问的数据,而右侧(NEXT)则是最旧的缓存。这个链表的作用是维护缓存的访问顺序,确保在缓存满了的情况下能够进行时间复杂度为O(1)的缓存增加与删除操作。
而cache是个字典,它的键是由函数参数生成的哈希对象,和链表结点里的KEY是同一种东西。而字典的value则是不一定的,在不同情况下存的东西并不一样,但抽象意义上来讲都可以理解为函数返回结果,它的作用就是用来快速获取缓存中的函数返回结果,时间复杂度为O(1)。
这么说还是有点抽象了,先看代码,官方的实现里对maxsize的两种特殊情况做了单独实现,一种是不需要缓存的情况,一种是缓存没有上限的情况。
1 | if maxsize == 0: |
第一种没啥说的,简单提下第二种,这里cache的value直接存的是函数的返回结果,逻辑很好读懂,如果有缓存则返回缓存,没有则调用user_function,并将函数结果缓存起来。setinal的作用就是作为唯一标识,判断函数结果是否已经缓存了,不用None是为了防止有些函数返回的可能就是None。并且由于上面对字典的操作都是线程安全的,所以也用不到锁。而且我们发现这里也压根没用到链表。
接下来就是第三种,设置了maxsize的情况。
1 | # ... |
这部分主要分为两部分逻辑,缓存命中和未命中。前面初始化的链表和锁到这里才派上了用场。
缓存命中时,需要把原先的缓存节点移动到root节点的左侧,作为最近访问节点。
而未命中时,需要先调用user_function获取结果,然后又出现了两种分支逻辑:缓存满了和没满。
如果没满,就只需要简单地把新节点插入到root前面即可,记得更新下full变量。
如果缓存满了,就把新结果放进当前root节点,最旧的缓存节点设置为新的root,并清除数据,更新cache。
这里配合下面的数据结构图可能会好理解一点。
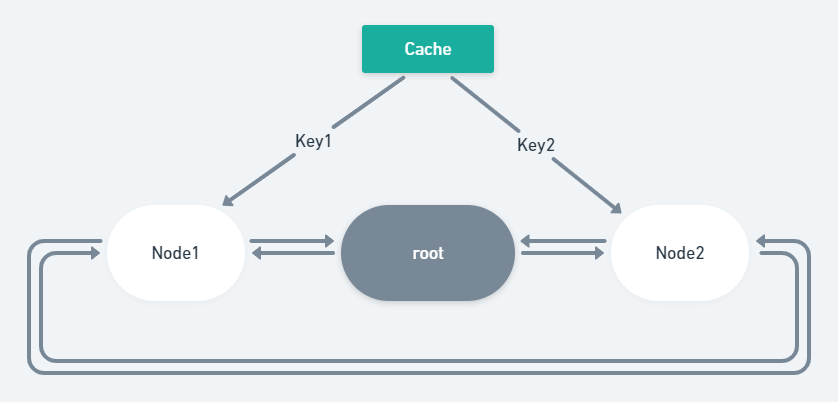
剩下的其实是些相对不太重要的代码了,就是对外暴露一些操作接口,这里不贴上来了。
看完源码后,现在知道工作原理了,其实要实现过期功能,就只需要在旧的逻辑里,插入处理过期逻辑的代码即可。这里就说下大致思路,不贴代码了。完整代码可以点这里查看。
- 当
maxsize为0的时候,没有缓存,所以不变。 - 当
maxsize为None的时候,即缓存没有上限,我们对字典的value稍作调整,把函数结果和缓存时间一起存进去,然后在取值的时候,判断是否已经过期,过期的话就按照缓存未命中处理,重新调用user_function并缓存结果即可。 - 当
maxsize为大于0的时候,我们把缓存的时间一并存入到链表的节点里,只被动过期,在命中缓存的时候,判断是否已经过期了,是的话,就把节点移除掉,当然也要记得更新cache,然后按照缓存未命中的逻辑继续往下走就行了。
大致逻辑是这样,剩下的都是一些细节上的处理。另外我在重新实现的时候,重新封装了一个类来作为链表的节点,而不是像官方那样用的数组,差不多就这些了。